Recent Projects
Automating Reproducibility Checks for Journal Submissions
Inspired by conversations at the IGDORE Reproducibilitea journal club, this project aims to automate the simpler aspects of the reproducibility check process for code submitted alongside a journal article. I developed a script that parses a codebase and notifies users of the following barriers to reproducibility:
- Files that are referenced in the code but are missing from the codebase
- Absolute paths to files that are machine-specific (e.g.
“C:/Users/Desktop/Data/data.csv”)- Paths which are not resolvable (the locations don’t exist in the database) are caught
- Paths which are resolvable (the locations do exist) are replaced with relative paths
(e.g.
"../Data/data.csv”)
This project is still in development, and a full codebase will be released soon. A demo of the proof of concept can be found here, and you can try scanning a single file for yourself below (requires javascript to be enabled)
Detecting Post-Retraction Citation Awareness
This project used natural language processing of the fulltext of openly accessible research works to discern whether an article that cites a retracted article did so knowingly (acknowledging the retraction) or not. I
began the project with the intention of providing data to inform the discussion in metascience about whether
and how damaging post-retraction citations really are.
Prior attempts at classifying post-retraction intent used rule-based heuristics (e.g. "Does the citing sentence include the word retracted in it? Does the paper also cite a retraction notice?"). The semi-manually annotated datasets that came from this prior work allowed me to instead take a machine learning approach that made no prior assumptions of which textual or metadata features would be meaningful.
- After data preprocessing and hyperparameter optimization, the best performing model achieved an F1 score of 0.95 (accuracy=95%, recall=0.96, precision=0.94)
- Because the model was trained on PubMed's open access corpus with a bias towards biomedical research, I tested another model with every field-specific research keyword removed from the feature set. Accuracy was similar (F1=0.92, accuracy=91%, recall=0.92, precision=0.92), suggesting this method may generalize beyond this corpus
- Papers that the model incorrectly detected as acknowledging the cited work's retracted status were often cases where the authors nontheless had serious reservations about the cited work or were expressing contradictory evidence. This suggests textual analysis tools may be useful in quantifying or predicting scientific dispute or future retraction.
- As expected from a rule-based classification method, the dataset annotated by Hsiao & Schneider 2022 had many false negatives (papers that acknowledged the cited paper was retracted but, e.g., didn't use the word "retracted" in the citing context). For small datasets, an iterative approach of training and manually correcting can improve classification performance.
- Even when using the authors' classification method, expanding the citation context to consider the entire paragraph the retracted work was cited in (instead of a few sentences on either side of the citing sentence) was enough to correct many of the previous false negatives.
- Even after a few rounds of manual correction, most correct detections of knowing citations included the cues from the original paper ("retract*", cites retraction notice, etc), suggesting my model was likely reproducing many of the same false negatives of the original authors' annotations. A larger, more field-unspecific dataset manually annotated without first relying on rule-based heuristics is needed to validate this technique
Features highly predictive of knowingly citing the retracted work
| Text Feature | Example | Source |
|---|---|---|
| "earlier" | "We have earlier reported our results interpreted... but we withdrew this report as..." | link |
| "origin*" | "...The publication provoked an academic debate, resulting in eighteen letters to the editor of the journal and the original article being retracted." | link |
| "withdr*" | "Subsequent work revealed that the proliferation data described in the initial report could not be replicated and the report was withdrawn" | link |
Features highly predictive of unknowingly citing the retracted work
| Text Feature | Example | Source |
|---|---|---|
| ", suggest*" | "Increased intracellular Pb has been linked to an increase in secreted levels of the AD-causing Aβ…Furthermore, increased levels of Aβ…may be associated with poor learning and memory performance as observed, suggesting a causative relation between…Some studies pointed out that SIRT1 may influence both Aβ and neurofibrillary tau pathology in the transgenic mouse models of AD (Herskovits and Guarente, 2014)." | link |
| "decrease"1 | "For assessment of the systolic function of the heart, fractional shortening and ejection fraction (EF) were used…This is in line with that found in a study by Laaban et al. [41] who described decreased eject fraction…Ejection fraction and fractional shortening correlated with age has already been described previously [43]." | link |
Footnotes
-
Here the retracted citation is [43], and the word "decreased" is not being used in reference to the citation, but its presence indicates a routine description of scientific findings, the kind of routine description where retracted works often were unacknowledged.↩︎
Hijacked Journal Detection Toolbox
Inspired by Anna Abalkina’s reporting on the hijacking of the Russian Law Journal, I used Crossref’s API to investigate how these paper mill articles were able to receive valid DOIs, and discovered a new method fraudsters are using to spoof the identity of journals they are hijacking. Rather than just buying the web-domain or typosquatting a similar web domain, they are able to register DOIs under the same journal title in 3rd party DOI provider databases like Crossref.
Loading...
Loading...
Loading...this can sometimes take up to 10 seconds or more
Discovering Unreasonable Citation Stacking
I’m developing an algorithm to scan the scientific literature and identify authors that have an unusually high number of papers with signs of citation stacking (the presence of many citations to a single author (or group of authors) that are not the result of honest scientific work but rather the result of gaming citation metrics). I’m planning to turn this into a package that is inter-operable with many types of data sources (Scopus, Crossref, OpenAlex) for others to use. Inspired by El País’s reporting on a case of extreme self-citation stacking among an esteemed computer scientist.
Here are a few easily detectable ways in which the standard citing pattern can be manipulated:
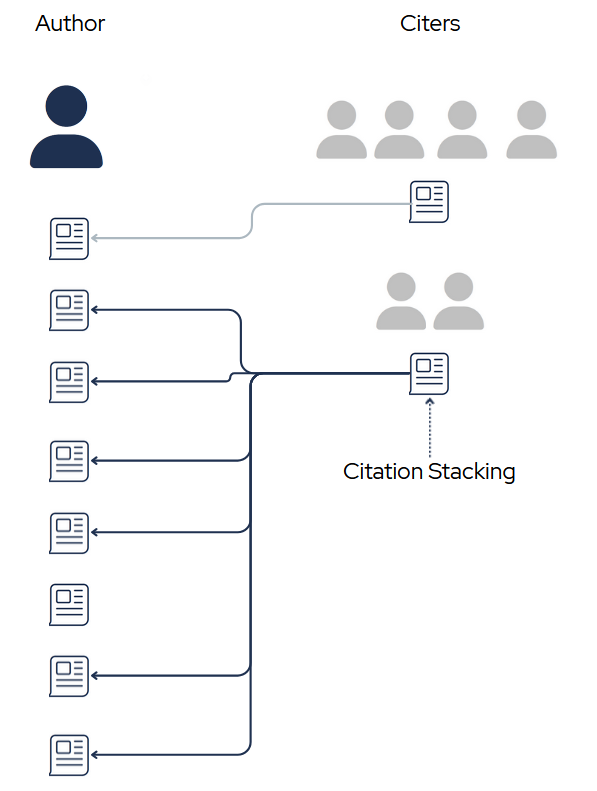
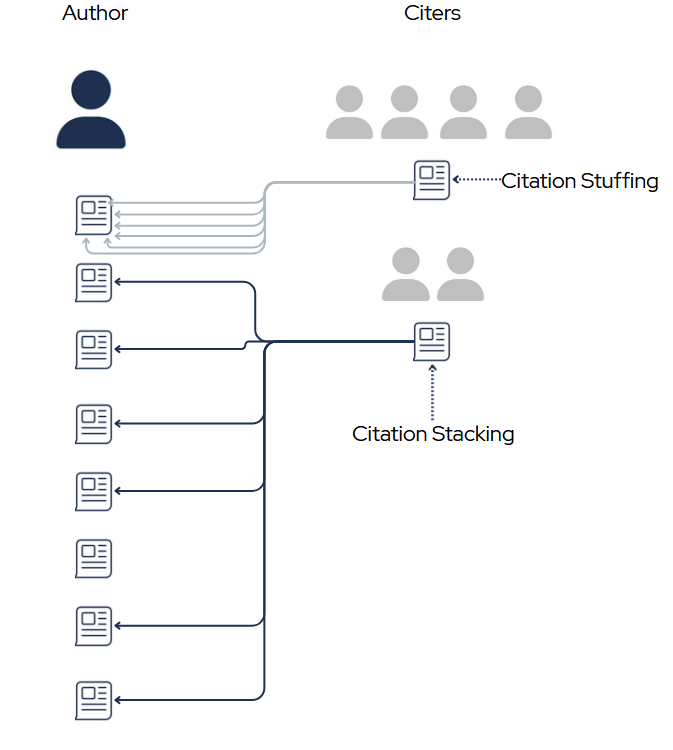
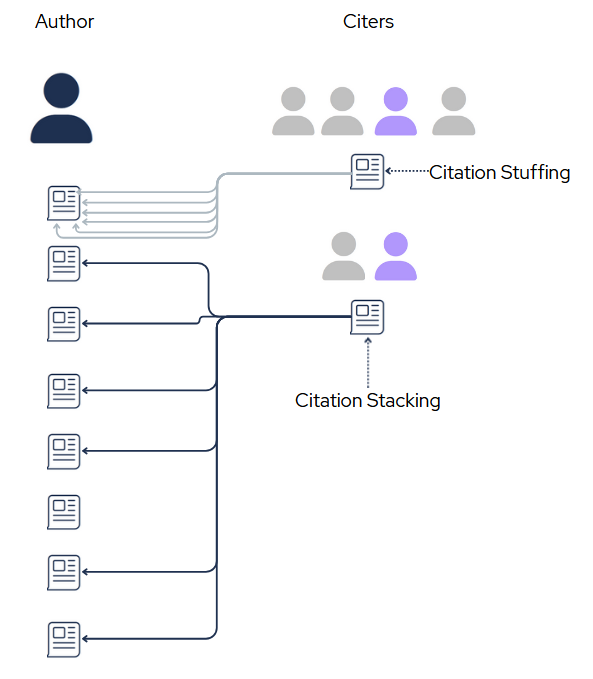
Here one individual (purple) seems to be highly influenced by the author's work. Signs of this pattern are 1) citing many different works of the author in their own papers (potential stacking) and 2) citing a single work of the author many times in their papers (potential stuffing). These for any given author, these individuals can be detected merely by using metadata provider APIs (e.g. Crossref, Scopus, OpenAlex). Further inspection can determine if the influence is undue (evidence of citation orchestration) or the result of legitimate academic dialogue. One example of such dialogue is that scholarly books on the history of Albert Einstein's theory of relativity would not only cite many of Einstein's papers, but also may cite individual papers many times. I am exploring ways to normalize repeat citations by the length of the citing scholarly work.
Predicting Paper Acceptance Status from Peer Reviews
I used Computer Science conference paper peer reviews to train a ML model to predict whether the paper was accepted or rejected. If done well, algorithms like these can lighten the load of editors’ jobs by helping them synthesize or make decisions on acceptance/rejection altogether (though much improvement must be made before that responsibility can be safely passed, if that's even possible). First attempts had poorer performance than I had hoped for (~0.65% accuracy, ~0.55 F1), so I am looking to revamp with a more sophisticated feature representation that will hopefully capture more nuance.
Older Projects
Detecting and Denoising EEG Artifacts
Replicating the results of Li et al. 2023. Created semi-simulated noisy EEG data using an open dataset of common EEG artifacts to train a segmentation neural network to detect where artifacts occur. Although an adjustment needed to be made to match the codebase with the presented methods in the paper, the accuracy of the artifact detection network largely replicated. Approaches like these are promising, as artifact removal is both a highly time-consuming and bias-injecting step in the standard preprocessing pipeline of EEG experiments, however I seriously question the generalizability of this group’s model due to major flaws in the assumptions behind the ‘clean’ EEG dataset used in training.
Automatically Detecting Sleep Spindles on EEG
Replicating the best performing algorithm from Lacourse et al. 2018 and comparing to a replicated version of Lustenberger et al. 2016. Adding fuzzy logic to the sliding window reduced false negatives on by-event analysis due to singular sample outliers.
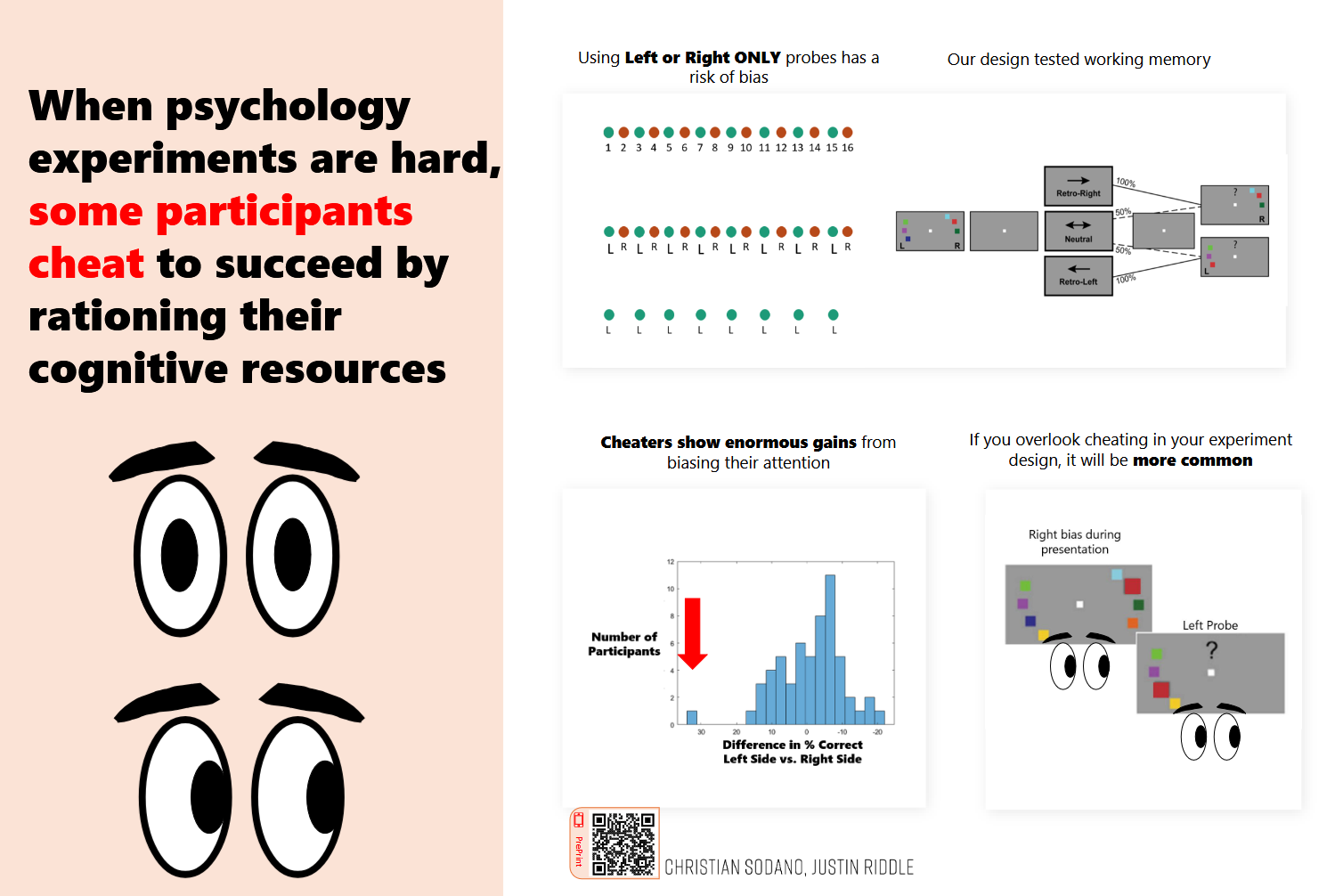
Cognitive Task Anti-Cheating
Spinoff analysis that came from working on a working memory cognitive task experiment where participants were instructed to attend to the center of their visual field and were prompted to recall stimuli according to, among other things, which visual hemifield the stimuli were presented in. Explored the feasibility of detecting a bias in performance on one side that would suggest participants are not attending to the center of their visual field, but rather ‘cheating’ to one side to improve their odds by minimizing the amount of information they must hold in their working memory.